The Content Transfer Tool (CTT) is essential if you have an existing Adobe Experience Manager (AEM) site or app and intend to migrate it to AEM as a Cloud Service (AEMaaCS). I contribute to the CTT as part of my day job, and wanted to share an in-depth, technical 2-part series on the phases of a migration. First up: Extraction.
There is lots to consider when planning & executing a migration. This post is going to assume you’ve read the official docs and explored the Cloud Acceleration Manager before attempting a migration on your own environment. If you do wish to follow along, you will need a source AEM instance (version 6.3-6.5) and a user who is part of the administrators group on your target AEMaaCS environment. I’ll be using an AEM 6.4 instance backed by an Azure Blob Storage data store, and my AEMaaCS environment is running the latest release at the time of writing (2021.7.5662).
With the latest CTT release installed on my source AEM instance — v1.5.4 at the time of writing — I’m ready to begin:
Creating the migration set
While not technically part of the extraction, it is the starting point so we’ll cover it quickly.
Note that if you’re going to “Include versions”, it is advised to add /var/audit as one of the Paths to migrate, since this is where some of the Assets timeline metadata is stored. Here’s my migration set, just prior to hitting save:
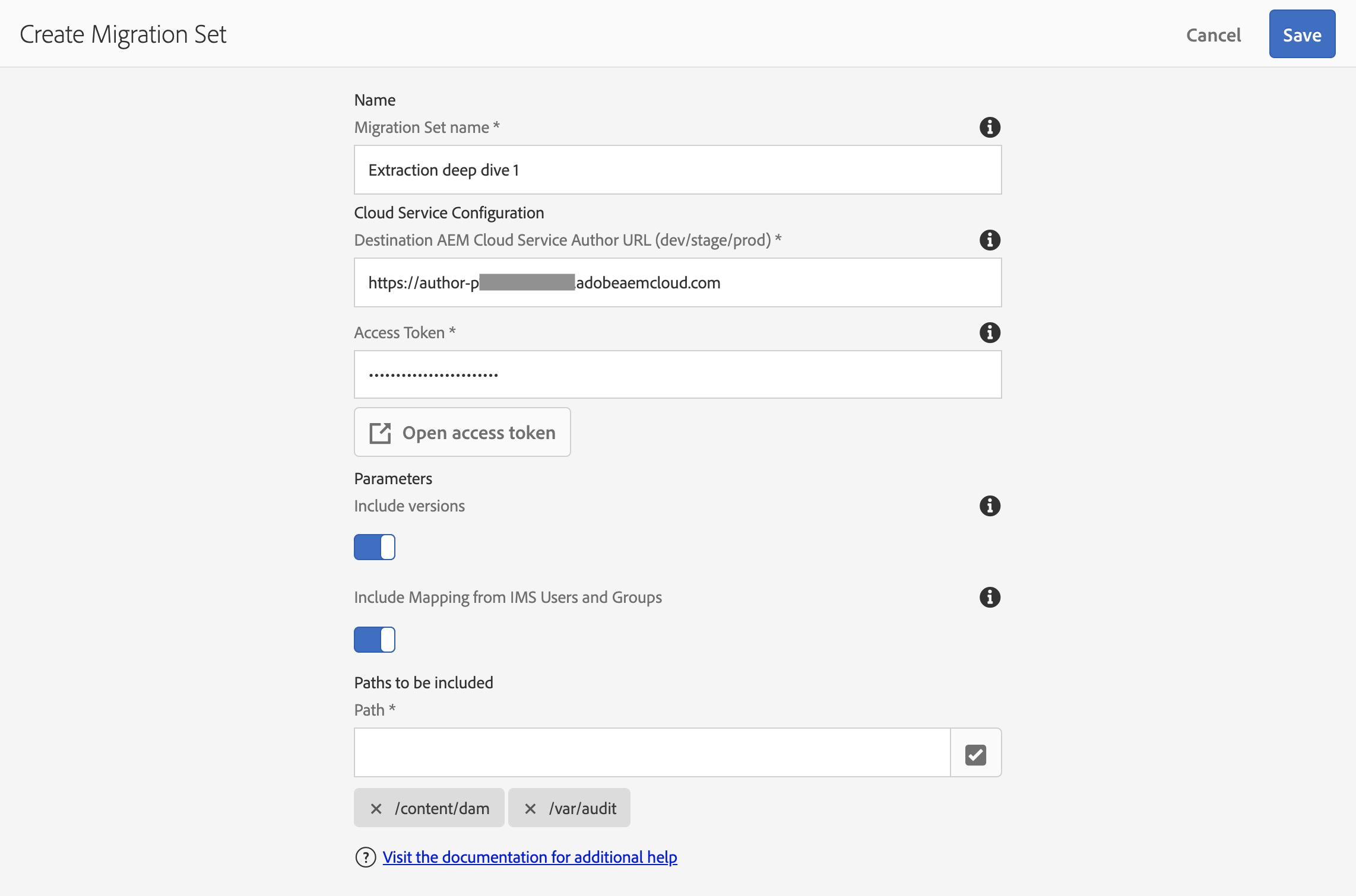
What should be put in “Paths to be included”, you ask? Any mutable content paths can be migrated by the CTT. Your AEM components, OSGi configs, and other immutable bits should be checked in to Git and pushed up to the program’s Cloud Manager repository instead. The AEM Project Structure doc has more detail on these concepts.
The initial Extraction
“Select the migration set you just created and click the Extract button already!” I can hear you urging. But we’re not quite ready just yet.
As stated above, my source instance is using an Azure Blob Storage data store. This means that the majority of the binary content in my AEM instance — images, videos, documents, etc; typically any file greater than 16kb — is already stored in the cloud. So why is this environment detail relevant to our initial extraction?
The majority of the time & effort spent during a typical extraction is to transfer all the large binary objects — or blobs, if you prefer — from the source AEM instance to the migration container (a temporary Azure Blob Storage container allocated for each migration set). Speeding this step up can reduce the total extraction time from a ballpark of 10 days to less than 10 hours (!) for a ~10 TB data store.
The exact process to enable this binary pre-copy step for Amazon S3 or Azure Blob Storage data stores are covered in the Handling Large Content Repositories doc page, which includes important notes on the use of this feature. To enable it for my instance, I had to install AzCopy and add the following azcopy.config file to the crx-quickstart/cloud-migration/ directory:
azCopyPath=/usr/local/bin/azcopy
azureSas=https://bruceblobs.blob.core.windows.net/azure-aem-64?sig=TOP_SECRET_SIGNATURE
Your own Azure SAS URI, or S3 connection details, will need to be provided in this file to enable AzCopy to orchestrate a transfer between AEM’s container and the migration container.
With azcopy.config in place, the transfer is ready to proceed. Select the migration set and click Extract to open the following dialog:
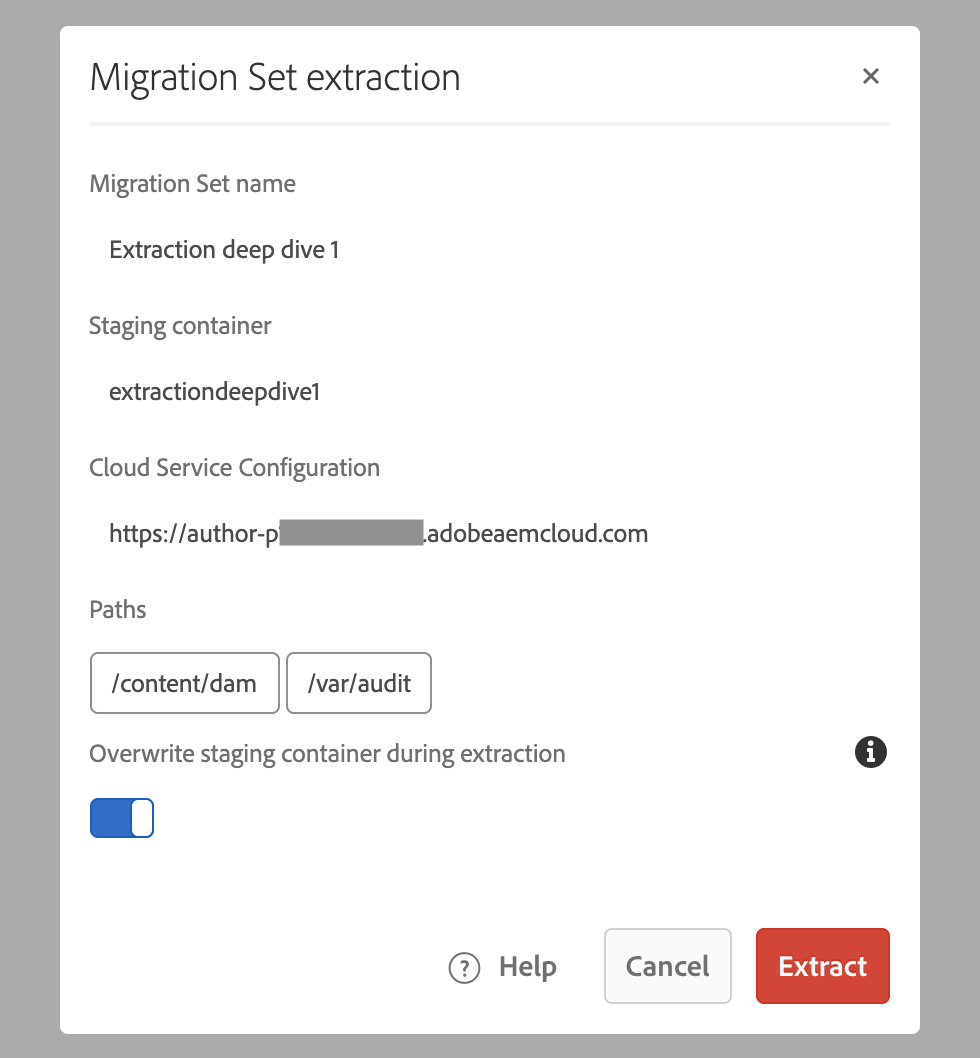
To “Overwrite staging container” or not?
There is one option in this dialog which can have a big impact on subsequent “delta” or “top-up” extractions. So what does this toggle actually do?
During the initial extraction this toggle has no effect. Since there isn’t actually a migration container created until the extraction begins, there is nothing to overwrite.
However, during subsequent extractions, this setting should almost always be toggled “off” to minimize the time that the extraction will take.
However, there is one scenario when “Overwrite staging container” should be toggled “on” for an extraction: if you need to make changes to the Content Paths that are included in a migration set. To illustrate, let’s say we added a content path and ran a “top-up” extraction without overwriting the staging container. The extraction would fail quickly with this message in the logs:
[main] ERROR c.a.g.s.m.commons.ContentExtractor - The passed list of paths and the include version parameters doesn’t match the current migration set
What actually happens to the migration container when this flag is set? If you were to observe the migration container after an initial extraction, but prior to a top-up with “Overwrite staging container” toggled on, you would see a number of blobs, an aem directory containing the migration set’s segment node store, and a locks directory. For example:
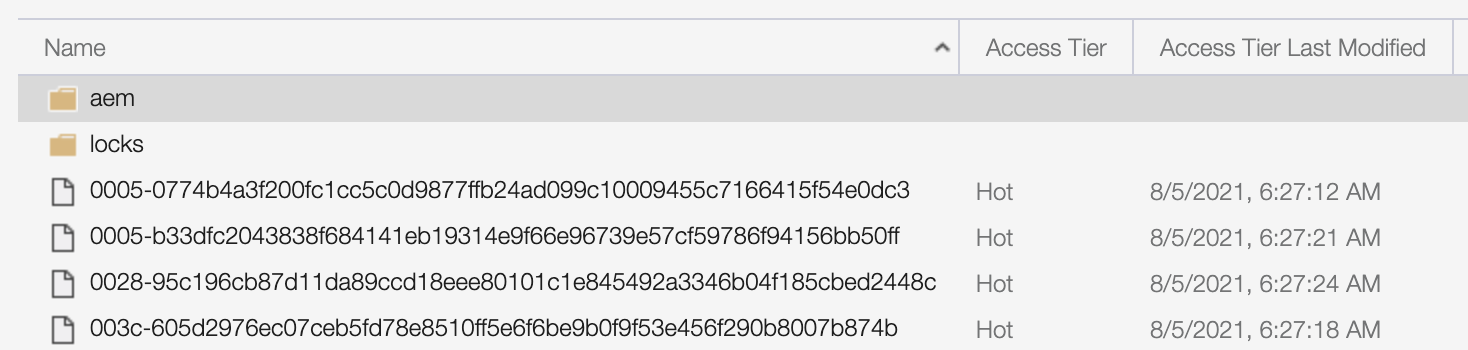
When a subsequent extraction is started with “Overwrite staging container” toggled on, the aem directory will be removed. This means that the migration set is essentially starting from scratch and must rebuild its temporary segment store from the content in the source AEM instance.
Note that the blobs themselves will not be removed, so an extraction with “Overwrite staging container” toggled on is not starting completely from scratch; any blobs that exist in the migration container which match the SHA-256 name of a blob in the source will not need to be re-uploaded.
How long will it take?
Speaking of time, how long is this process going to take? The short answer, as always: it depends. And what it primarily depends on for extraction is the total size of the source instance’s data store, assuming nearly everything is being migrated to AEMaaCS. Network bandwidth, cloud region, and system resources can factor in too, of course.
The best way to gain a ballpark estimate of extraction time is to use the Cloud Acceleration Manager’s Content Transfer Tool Calculator:
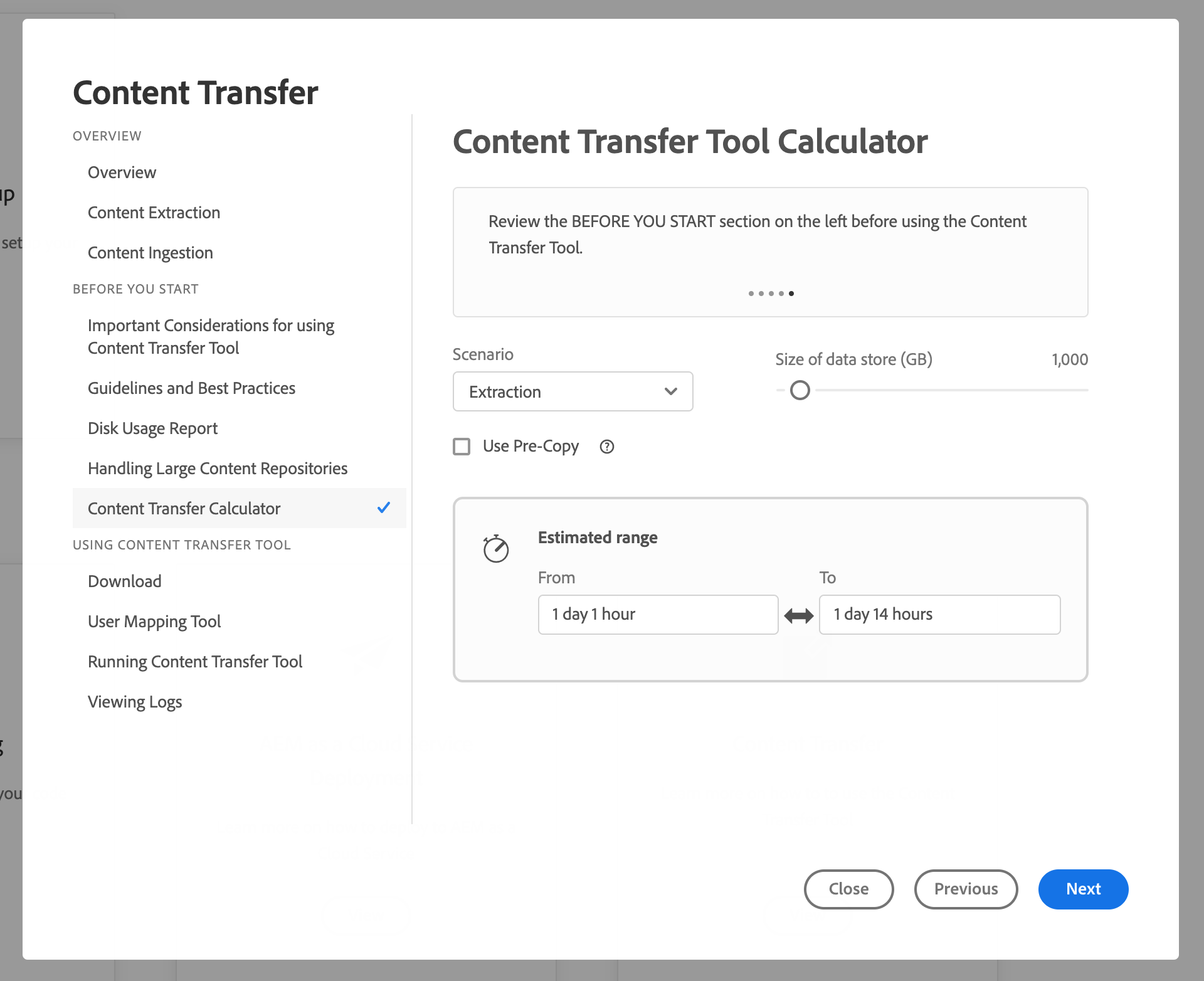
Make sure to check the “Use Pre-Copy” checkbox if an AzCopy binary pre-copy has been configured.
Interpreting the logs
While an extraction is running, I encourage you to check out the extraction logs via the CTT user interface in AEM. Pro-tip: you can click directly on the RUNNING status to be taken directly to the logs of a migration set:
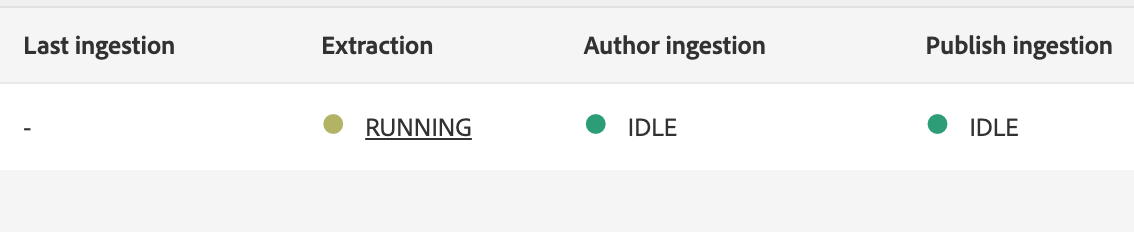
The logs can be quite verbose as the extraction progresses. I’ve included a few common errors below that may help you diagnose your own failed extraction.
Connection/firewall issues
Log pattern:
com.microsoft.azure.storage.StorageException: An unknown failure occurred : Connection refused (Connection refused)

This means that the migrator process — a Jar started by AEM to coordinate & execute the extraction — has failed to connect to the migration container.
The workaround for this depends largely on the network configuration of the instance running your source AEM environment. It may be necessary to enable connections to blob.core.windows.net via a firewall rule, or there may be other mechanisms in place which are preventing a connection to Azure.
Invalid AzCopy pre-copy configuration
Log pattern:
com.adobe.granite.skyline.migration.commons.azcopy.AzCopyProcessException: AzCopy pre-copy phase terminated with exit code=1. Stopping extraction.
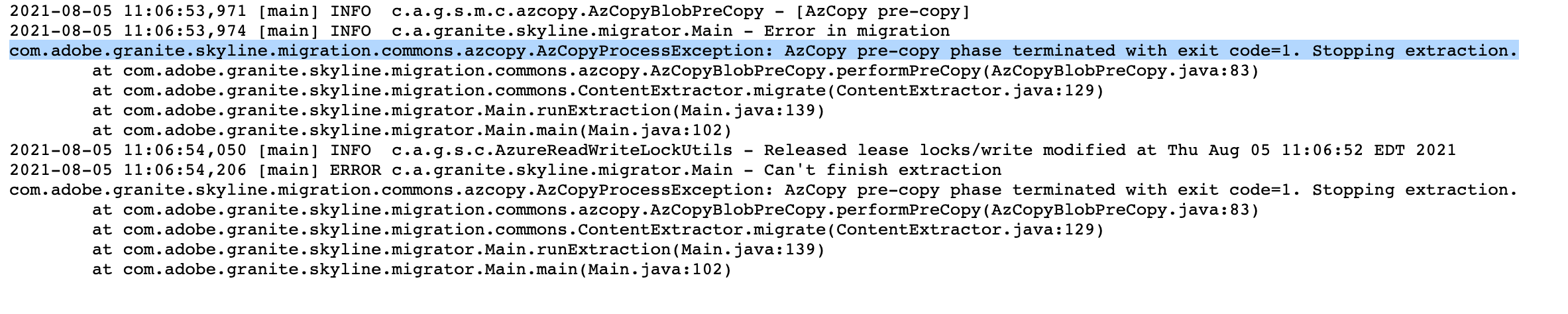
If you provided an azcopy.config file per the instructions in Handling Large Content Repositories, but the AzCopy process was unable to coordinate a blob copy, then this error will appear and the extraction will fail.
The AzCopy logs immediately prior to this error will provide context as to why this happened. In my case, AuthenticationErrorDetail: Signature fields not well formed was the culprit (since I manually tweaked the signature to get the error to happen). This error can also occur when the SAS URI provided in azcopy.config has expired, or if the S3 container coordinates or access key pair are invalid.
Missing blobs
Log pattern:
org.apache.jackrabbit.core.data.DataStoreException: Cannot retrieve blob. identifier=BLOB_ID

This issue can occur if a blob referenced in AEM cannot be found in the source data store. We’ve seen this error before when an extraction is attempted from a clone of a production environment, and an access policy is not set up on the cloud provider to prevent the deletion of blobs. In this configuration, if the source AEM instance were to delete an asset, or a blob containing index data were removed, this could result in a blob missing during extraction which is still referenced by the clone.
Next steps
I hope this post has helped de-mystify some of the technical aspects of an extraction that happen behind the scenes. If I could sum things up:
- “Overwrite staging container” should almost always be off, unless you have changed the paths included in the migration set
- Leverage the AzCopy pre-copy step for large data stores that use Amazon S3 or Azure Blob Storage
- Observe the logs to determine the root cause of a failed extraction
Stay tuned for part 2 in this series: Everything you wanted to know about Ingestion - coming soon!
